

How well do you know the internet? Socializing on social media platforms like Facebook and Twitter, watching YouTube videos, reading popular blogs & news websites, conducting searches using popular search engines like Google & Bing will not make you a professional internet user, as everything you see on these places is simply a part of the surface web which only constitutes 4% of the entire web contents!
Cyberspace is huge and it is bigger than what we see when surfing the internet and doing our regular browsing tasks. No one can predicate the exact size of the web. Nevertheless, the continual adoption of IT in all life aspects in addition to the increased number of internet users day after day will certainly increase web content to unpredictable rates.
As I already said, most internet users only access the surface web when doing their regular online tasks. The surface web is the portion of the web that typically search engines can access and index its contents. The second layer of the web is the deep web. This layer is the largest one in size and contains within it another hidden sub-layer which is the dark web – or darknet. Surface and deep web can be accessed using a regular web browser like Firefox and Chrome. However, things are not the same with the darknet, which needs special software to access.
In this article, I will discuss the different layers that form the web and describe what we expect to see on each layer. However, before I begin talking about the web layers, readers should be able to differentiate between two terms that most internet users use interchangeably which are: The World Wide Web (WWW) and the Internet. For instance, the Internet is the network – and the IT infrastructure – used to access contents on the Web, while the Web is the collection of information – webpages – accessed via the internet.
Surface web
Also known as the visible or clear web, the surface web is the portion of the web that can be indexed and accessed using standard search engines like Google, Yahoo! and Bing, it constitutes about 4% of web content and can be accessed using standard web browsers without using any additional software.
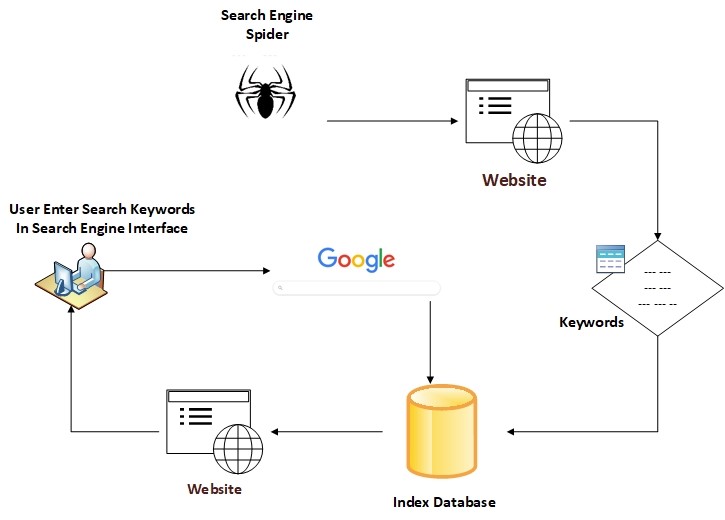
Regular search engines index web content by sending robots (also known as crawlers or spiders) to discover new and updated content. These crawlers travel across the internet and discover new content by following hyperlinks in the visited domain name. For example, when the crawler visits the home page of http://www.example.com, it will click – and follow – all hyperlinks on the home page and add the URL of each discovered page to the search engine index database.
When a user wants to use a search engine to look up something online, he/she need to supply a search query (or keywords), now the search engine looks up the searchers query in the index database and fetch the results accordingly, starting from the most relevant and ending with the least one (see Figure 1).
Deep web
This layer constitutes the largest portion of web content (about 96%). It contains all contents that standard search engines cannot index for different reasons, such as content hidden behind login forms that need credentials to access, public databases that require a user to supply a search query to retrieve information from it, fee-based content – like digital libraries, some online magazines, and news channels – that require registration and paying a fee to access in addition to some file types that search engines cannot index.
| You can see a list of file formats that the Google Search Appliance can crawl, index, and search at: https://support.google.com/gsa/answer/6329277?hl=en |
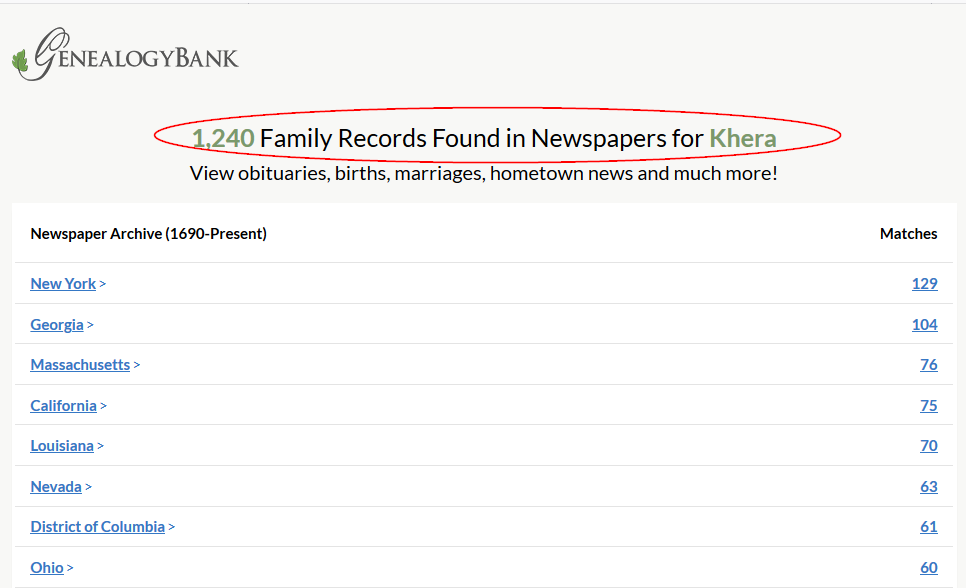
An example of deep web content stored in buried online databases is the genealogybank (https://www.genealogybank.com). To retrieve information from this database, you need to supply family last name and hit the “Begin Search” button (see Figure 2).

Now, the internal search function of the website will search its database and return relevant results (see Figure 3). Standard search engines cannot index online database contents because search engines spiders are designed to follow hyperlinks and are not designed to enter search queries and submit search forms to extract results.
Darknet
The dark web is a subset of the deep web; it is a collection of private networks (darknet) that constitute what is known as the dark web. We cannot access the dark web sites using regular web browsers, as they need a special software (such as the TOR browser) to access (See Figure 4). Besides, dark web content is encrypted and cannot be indexed using conventional search engines, which makes browsing darknet contents relatively difficult compared with the surface net. The name “Darknet” is usually associated with illegal and criminal activities. However, a good portion of it is used for noble purposes (e.g. Human rights activates and journalists who want to keep their identity and online communications anonymous). The most popular darknet networks: TOR, I2P and the Freenet.
No one knows the volume of the dark web as there is no way to index its contents, however, a recent study by Recorded Future company found about 55,828 different onion domains on the TOR darknet (TOR websites use the .onion extension as a top-level domain (TLD)).

Conclusion
Understanding how to mine information from the deep and dark web becomes an essential skill for any cybersecurity professional working to protect IT systems in today’s digital age. A newly emerging field in cybersecurity is named “Cyber threat intelligence”, Threat Intelligence collect and analyze data from online public sources (the three web layers) to understand attacker’s motivation and predicate their future behavior. This gives decision-makers the needed insight to plan their future steps and to move from reactive to proactive defense.
Now that we know what is meant by the surface, deep and dark web, it’s time to dive more deeply and see how darknet can be accessed and searched, and this what I’m going to cover in my next article.

Dr. Varin Khera
Dr. Khera is a veteran cybersecurity executive with more than two decades worth of experience working with information security technology, models and processes. He is currently the Chief Strategy of ITSEC Group and the Co-founder and CEO of ITSEC (Thailand). ITSEC is an international information security firm offering a wide range of high-quality information security services and solutions with operation in Indonesia, Malaysia, Philippines, Singapore, Thailand and Dubai.
Previously the head of cyber security Presales for NOKIA, Dr. Khera has worked with every major telecom provider and government in the APAC region to design and deliver security solutions to a constantly evolving cybersecurity threat landscape.
Dr. Khera holds a Doctor of Information Technology (DIT) from Murdoch University, a Postgraduate Certificate in Network Computing from Monash University and a Certificate of Executive Leadership from Cornell University.
Dr. Khera was one of the first professionals to be awarded the prestigious Asia Pacific Information Security Leadership Awards (ISLA) from ISC2 a world-leading information security certification body under the category of distinguished IT Security Practitioner for APAC.
Leave a Reply