

What is eBPF?
By 2025, Gartner estimates that over 95% of new digital workloads will be deployed on cloud-native platforms, up from 30% in 2021. At the same time, Kubernetes is becoming the de facto standard for cross-cloud orchestration and a pillar of cloud native architectures.
A contributing technology that will play a big role in this transition is the extended version of the Berkeley Packet Filter (eBPF). eBPF enables programs to run in kernel of the host operating system (Linux, first, and now also Windows), and to instrument the kernel without changing kernel source code. eBPF programs are portable between kernel versions and atomically updateable, which avoids workload disruption and node reboot. eBPF programs can be verified at load time to prevent kernel crashing or other instabilities.
eBPF is an abstract virtual machine (VM) with its own instruction set that runs within the Linux and Windows kernel. eBPF can execute user-defined programs inside a sandbox in the kernel. Those sandbox programs are triggered by events in the kernel, receiving pointers to kernel or user space memory.
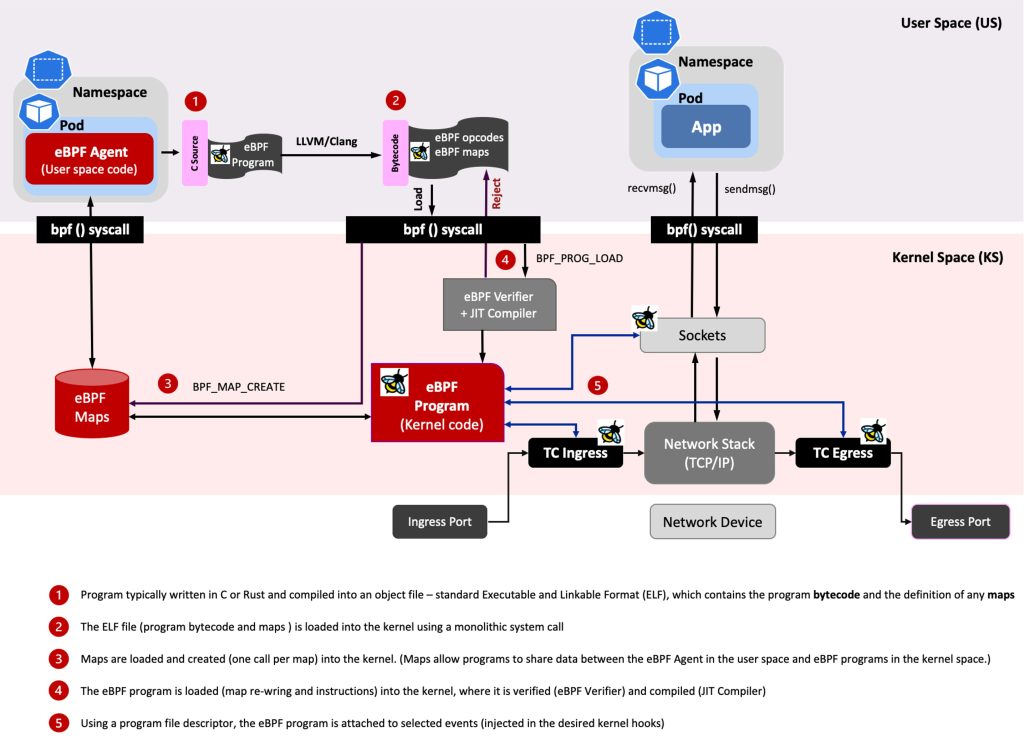
The eBPF project layout consists of three pillars (see Figure 1):
- eBPF programs, running in the kernel and reacting to events.
- User space programs, loading eBPF programs to the kernel and interacting with them.
- BPF Maps (hash maps, arrays, ring / perf buffer), which allow data storage and information sharing between the user space programs and eBPF programs in the kernel.
In the development phase, see Figure 1, the eBPF program bytecode is injected into the kernel. Generally, the eBPF program is written in C or Rust and compiled as an object file. This is a standard Executable and Linkable Format (ELF) file that can be analysed using tools such as readelf and it comprises both the program bytecode and the definition of any maps. The Linux kernel expects eBPF programs to be loaded in the form of bytecode. A compiler suite like LLVM can be used to compile pseudo-C code into eBPF bytecode.
The eBPF Maps enable eBPF to share acquired information and preserve state. As a result, eBPF programs can utilize eBPF maps to maintain and retrieve data in a variety of data formats. The eBPF maps can be accessed through a system call from both eBPF programs and user space applications. Hash tables, Arrays; LRU (Least Recently Used); Ring Buffer; Stack Trace and LPM (Longest Prefix Match) are examples of support maps.
In the runtime phase, a (Go) Library loads the eBPF program into the kernel using an eBPF system call. Then, the kernel verifies the code, and the Just in Time (JIT) Compiler compiles the eBPF program and attaches that to the desired hook. eBPF programs let the custom code run in the kernel when the kernel or an application passes a certain hook point (system call, function entry/exit, kernel trace point, network event, etc.). eBPF programs bring visibility between the kernel and user space using BPF maps.
As illustrated in Figure 1, when an eBPF program is loaded into the kernel, it will be triggered by an event (TC ingress/egress, and sockets, in the figure). Once the event occurs, the attached eBPF program(s) will be executed.
For example, running eBPF programs is possible using a set of eBPF hooks that are supported in the networking stack of the Linux kernel. Higher level networking constructs can be created by combining the following hooks:
- Express Data Path (XDP): the networking driver is the earliest point where it is possible to attach the XDP BPF hook. And when a packet is received, the eBPF program is triggered to run.
- Traffic Control Ingress/Egress: like XDP, by hooking the eBPF programs to the traffic control ingress, eBPF programs are attached to a networking interface. The difference with XDP is that the eBPF Program will run after the initial processing of the packet by the networking stack.
- Socket operations: Another set of hooking points are the socket operations hook that attach the eBPF program to a specific cgroup and triggers them based on TCP events.
- Socket send/recv: The socket send/recv hook triggers and runs the attached eBPF programs on every send operation performed by a TCP socket.
It is also possible to instrument function calls using Kprobes for kernel functions and Uprobes for user space functions. Security related actions can be taken using Linux Security Module (LSM) hooks (kernel 5.7, and later releases).
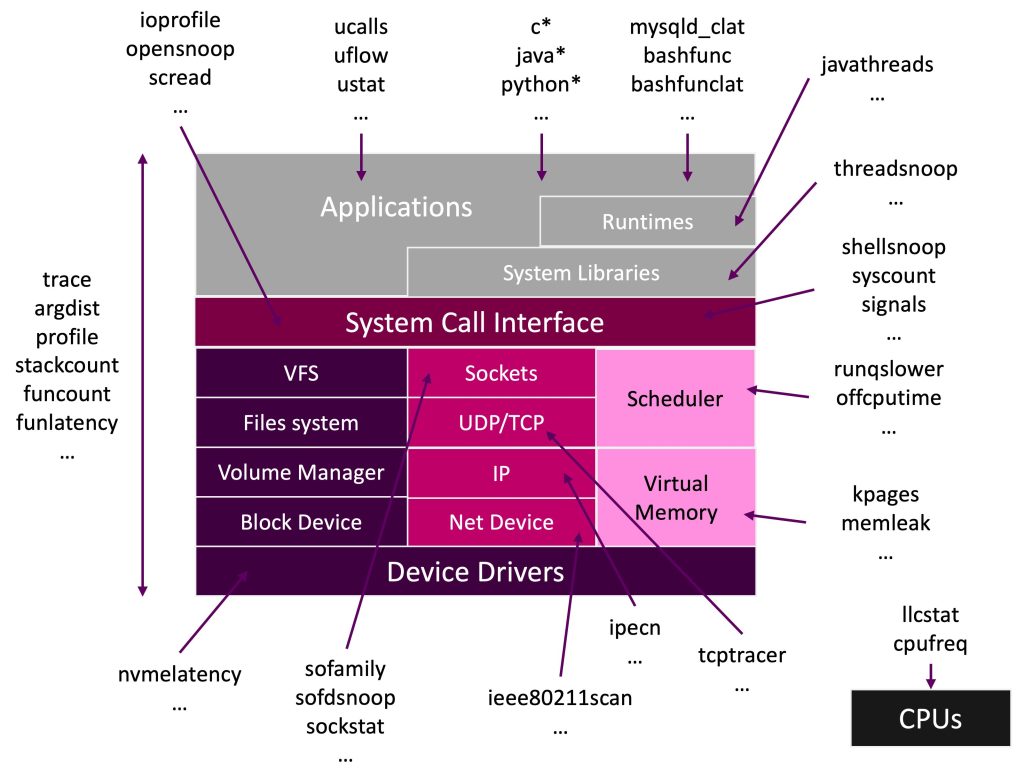
A comprehensive set of eBPF observability tools is illustrated in Figure 2. The figure gives an idea of the huge range of parts of the system can be instrumented with eBPF programs.
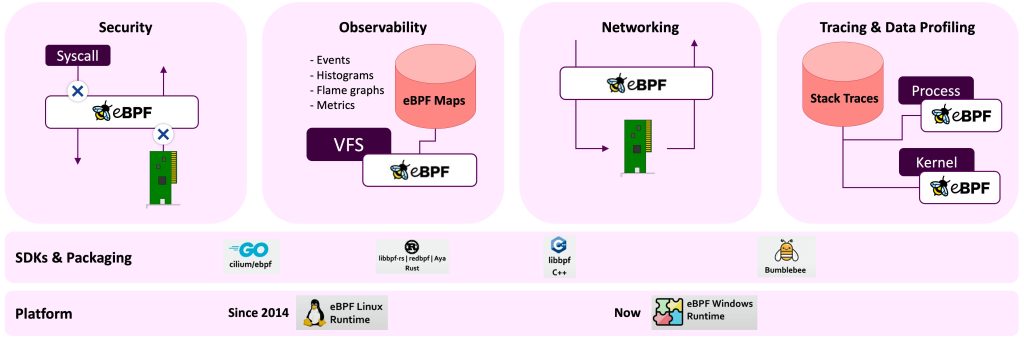
Thanks to the broad variety of events, eBPF programs can be utilized for efficient networking, tracing and data profiling, observability, and security tooling, e.g., for threat defence and intrusion detection. See the eBPF stack shown in Figure 3.
Why eBPF?
Cloud native architecture is one of the key drivers of eBPF based applications, as more kernel subsystems are becoming extensible using eBPF, drivers and soon kernel modules could be written in eBPF.
As already mentioned, typical use cases are security, networking, and observability. The intersection between security and networking leads to “network security” applications. The overlapping between security and observability yields “real time threat detection and response” applications. Networking and observability jointly are about “network observability” applications. “Intelligent application sandboxing” is the results of security, networking, and observability intersection, as illustrated in Figure 4.
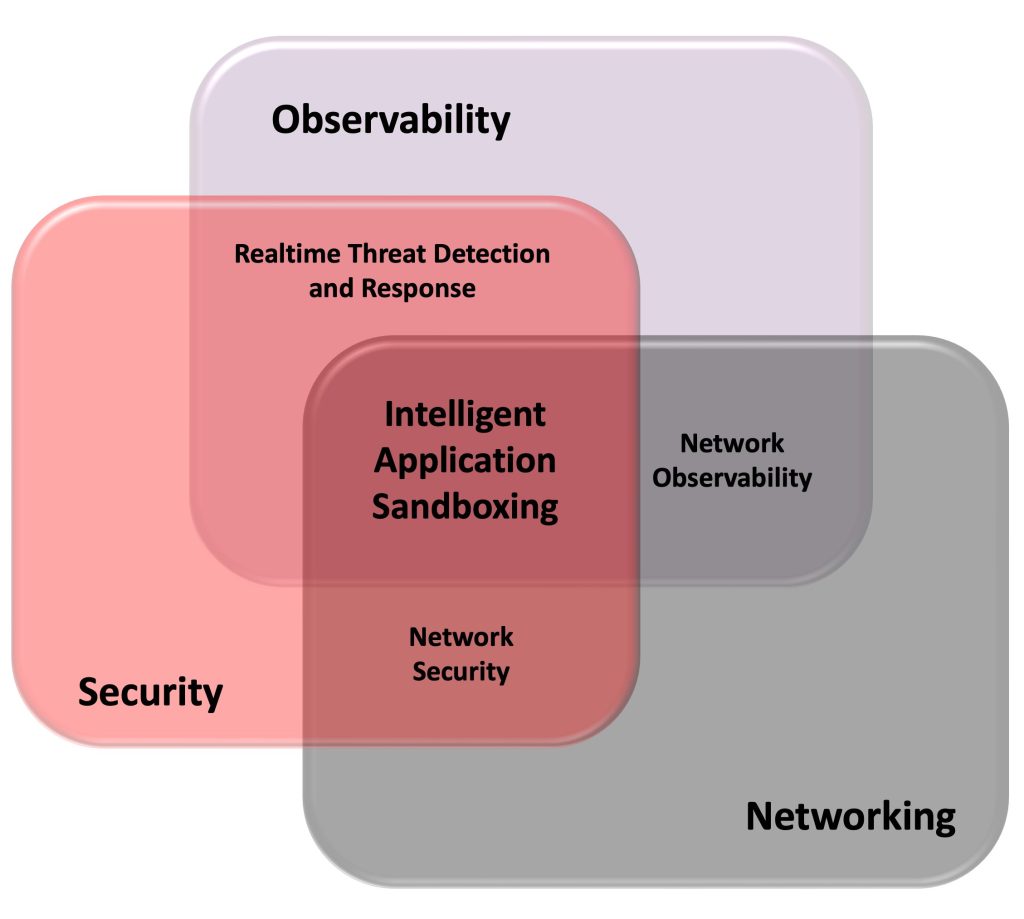
Figure 5 consolidates some of the values brought by eBPF to cloud native environments. eBPF shows an amazing programmability, the eBPF verifier ensures that the loaded programs are safe and guarantees that they do not crash the kernel. eBPF provides excellent visibility and enforcement control of policy and lets operators observe all programs running in the user space, which is hardly ever achieved by applications that operate in the same space. Moreover, eBPF presents low overhead, making it ideal for containers in production.
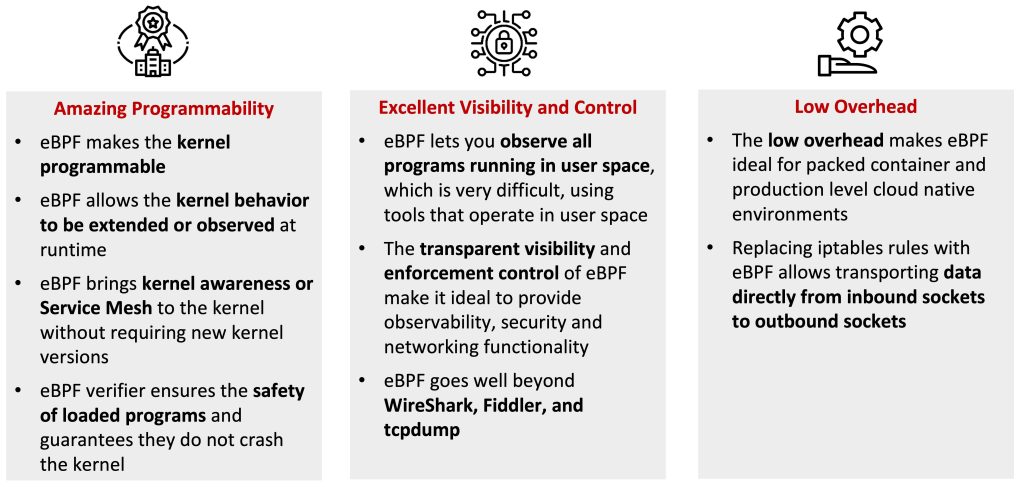
Furthermore, replacing the iptables rules with eBPF maps allows operators to transport data directly from inbound sockets to outbound sockets, which enables super-fast service load balancing with eBPF. An example of how load balancing, between four replicated pods in a Kubernetes cluster, is achieved using eBPF is depicted in Figure 6.
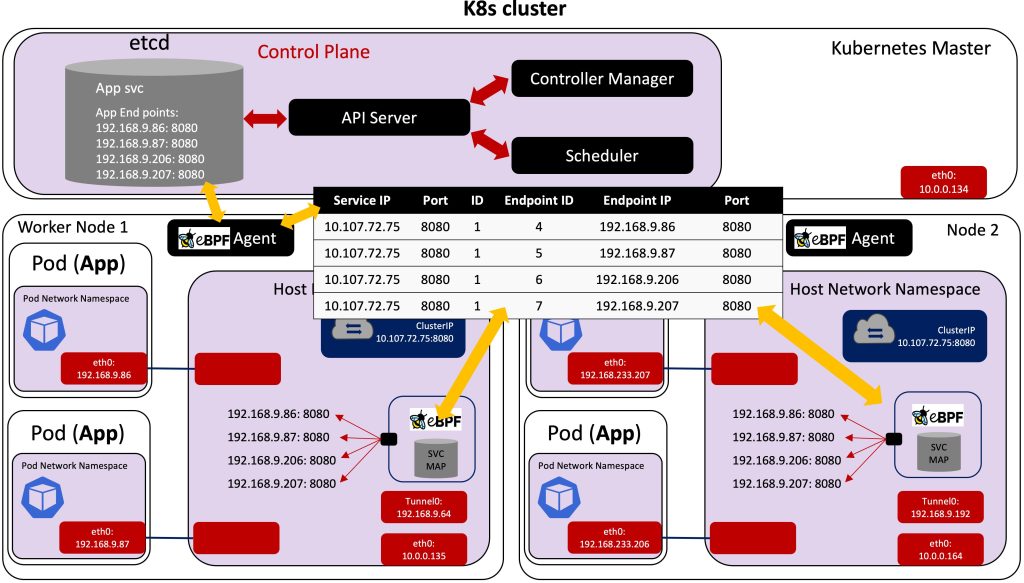
Table 1 outlines ten benefits of eBPF which showcases how this technology is expected to evolve to support many other use cases. Those include the possibility of using XDP and AF_XDP direct path, which blends in naturally with Kubernetes, as opposed to Data Plane Development Kit (DPDK); and achieve sustainable computing projects like Kepler, an open source power level exporting toll that shows energy consumption data via eBPF for Kubernetes clusters. Kepler collects data based on eBPF programs that attach to Linux tracepoints and performance counters to collect information such as process id, cgroup id, cpu cycles, cpu time, cpu instructions, cache misses etc. The aggregated data in conjunction with other stats in the user space are then used for estimating energy consumption by pods.
| # | As is | To be |
| 1 | eBPF speeds up development by decoupling from kernel releases | 5G data planes with eBPF, IoT security enforcement with eBPF exist today |
| 2 | eBPF shifts data processing closer to the event source (per-socket hooks, pre-cgroup hooks, XDP, etc.) freeing up resources | APM and security monitoring platforms with eBPF at its core |
| 3 | eBPF allows shorter production feedback loops, decoupling from kernel and allowing atomic program updates on the fly, and location aware processing | XDP & eBPF L4LBs/gateways into the cloud, memcaches/accelerators, etc. |
| 4 | eBPF moves traffic with significantly lower latency by BPF host routing and BPF bandwidth manager | XDP and AF_XDP blends in naturally with Kubernetes, as opposed to DPDK |
| 5 | eBPF provides building blocks from the kernel, which are too complex for other kernel subsystems | Traffic engineering via eBPF and SRv |
| 6 | eBPF (to some degree) fixes or mitigates kernel bugs on the fly | eBPF-based solutions are the preferred or default choice |
| 7 | eBPF enables low-overhead deep visibility and enforcement into the system, achieving significantly richer visibility, programmability, and ease-of-use than old-style perf | eBPF process scheduler (Google, Meta, Huawei) to customize, e.g., CFS for data center workloads |
| 8 | eBPF decouples from legacy UAPI and allows efficient data processing | eBPF and IMA for file integrity protection/monitoring of system software and user applications |
| 9 | eBPF is an enabler to build policy enforcement features around stronger notions of identity | eBPF and XDP-like layer plus better observability for storage devices, e.g., around block layer and below |
| 10 | eBPF allows developers to extend kernel but with a “safety-belt” on | Sustainable computing projects like Kepler exporting energy consumption data via eBPF for Kubernetes clusters |
Why eBPF now?
The market potential of eBPF is reflected in several significant company moves in 2022, including these examples:
- “New Relic acquires Pixie Labs, a next Generation Machine Intelligence and Observability.”
- “Datadog acquires Seekret and they are excited to leverage Seekret’s eBPF expertise to unlock new capabilities.”
Seekret uses powerful eBPF technology to autodiscover and visualize API assets, interconnections, and dependencies, enabling developers and product leaders to understand API behaviour and usage patterns in complex, dynamic environments.
The industry comprehends eBPF and a notable increase in the industry utilization and understanding of eBPF has created more buyers. At a major Kubernetes conference, the discussion was on eBPF with one commentator stating that “KubeCon was basically eBPF.”
The technology has reached its technical maturity. In fact, eBPF itself has become markedly more general purpose, particularly due to eBPF for Windows. Also, a series of eBPF toolchains, such as GCC and Aya – a library that makes it possible to write eBPF programs fully in Rust – have emerged.
How to monetise eBPF
We may think of a marketplace where customers may access the software through subscription and use a product-based pricing and billing model based on a user subscription plan linked to specific products (for example, network observability, runtime security, energy, etc.) and a data source plan, depending on service and support type, as depicted in Figure 7.
The user subscription plan considers the number of user accounts and the type of support required. The data source plan is linked to a usage-based pricing model. The data reported to the eBPF agent are processed and then transformed into bytes (usage metrics) using transformation rules, specific to the corresponding data source. If you’re on the usage-based pricing model, you’re charged for the number of bytes that are above and beyond the free per-month amount.
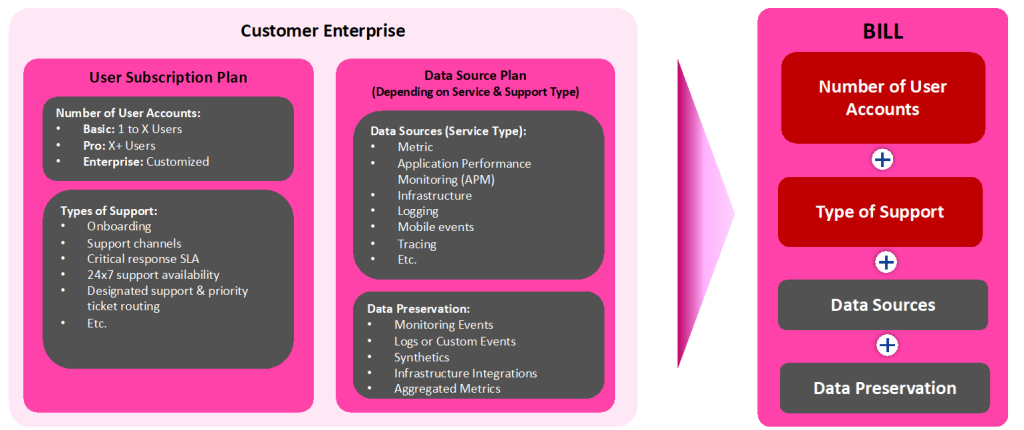
Another possibility is to charge based on resources, i.e., number of deployed controllers and agents (daemon sets), as depicted in Figure 1, and types of support (services).
Conclusion
eBPF is to the kernel as a JavaScript is to the Web browser. Although some challenges exist: eBPF development is not easy, eBPF is fast paced and hard to keep up with, implementation details may vary by kernel version, and there is no easy packaging / deployment solution. But this fundamental enabling technology is leading to a major wave of innovation in the kernel space, bringing immediate benefits in a cloud native environment, especially, due to its dynamic programmability, reliability, and ability to get great workload visibility with minimal disruption.
The fact that we can inspects packets gives us extremely performant observability tools that can be mapped to other aspects such as Kubernetes metadata and get in depth security forensics from the extracted information. We can use the ability to drop or modify packets for network policies and do encryption with eBPF for security. Also, since we can send packets and change the destination for a packet, eBPF allows us to create powerful network functionalities, such us load balancing, routing, and service mesh. eBPF enables next-generation service mesh because we do not need to instrument pods with sidecars and achieve high performance without any App or configuration change.


David Soldani
David Soldani received a Master of Science (M.Sc.) degree in Engineering with full marks and magna cum laude approbatur from the University of Florence, Italy, in 1994; and a Doctor of Science (D.Sc.) degree in Technology with distinction from Helsinki University of Technology, Finland, in 2006. In 2014, 2016 and 2018 he was appointed Visiting Professor, Industry Professor and Adjunct Professor at University of Surrey, UK, University of Technology Sydney (UTS), Australia and University of New South Wales (UNSW), respectively.
Dr. Soldani is currently at Rakuten. He has served as Chief Information and Security Officer (CISO), e2e, Global; and SVP Innovation and Advanced Research. Prior to that he was Chief Technology and Cyber Security Officer (CTSO) within ASIA Pacific Region at Huawei; Head of 5G Technology, e2e, Global, at Nokia; and Head of Central Research Institute (CRI) and VP Strategic Research and Innovation in Europe, at Huawei European Research Centre (ERC). David can be found on LinkedIn at https://www.linkedin.com/in/dr-david-soldani/ .
Leave a Reply